- 更新日 : 2026年3月18日
MODE関数の使い方:エクセルで最頻値を求めてデータの傾向を分析する方法
MODE関数は、データセットの中で最も頻繁に出現する値(最頻値)を求めるエクセルの統計関数です。最頻値は平均値や中央値と並ぶ代表値の一つで、アンケート分析、品質管理、売上分析、顧客行動分析など、様々なビジネスシーンで活用されています。
本記事では、MODE関数の基本的な使い方から実務での応用例、MODE.SNGL関数やMODE.MULT関数との違い、複数の最頻値への対処法やよくあるエラーとその解決方法まで、わかりやすく解説します。データの中心傾向を多角的に分析する手法をマスターしましょう。
MODE関数の使い方
MODE関数とは
MODE関数は、指定したデータ範囲の中で最も多く出現する数値を返す統計関数です。最頻値(モード)は、データの分布において広く用いられています。
平均値が外れ値の影響を受けやすく、中央値が順位のみに着目するのに対し、最頻値は実際に最も多く観測される値を示すため、実務的な意味を持ちやすいという特徴があります。
たとえば、店舗の時間帯別来客数を分析する際、最も混雑する時間帯を特定したり、製品の不良品分析で最も発生しやすい不良パターンを見つけたりする場合に、MODE関数が役立ちます。
基本構文
MODE関数の構文は次のとおりです。
=MODE(数値1, [数値2], …)
各引数について詳しく説明します。
数値1, 数値2, …:最頻値を求めたい数値データを指定します。セル範囲、個別の数値、配列などを最大255個まで指定できます。文字列や論理値は無視されます。
MODE関数の計算原理
MODE関数は以下の手順で最頻値を決定します。
- 指定されたデータから数値のみを抽出
- 各数値の出現回数をカウント
- 最も出現回数が多い値を特定
- 複数の値が同じ最高頻度の場合、最小値を返す
この動作を理解することで、結果の解釈が正確になります。
基本的な使用例
実際にMODE関数を使用してみましょう。
データ:1, 2, 2, 3, 3, 3, 4, 4, 5
=MODE(A1:A9) // 結果:3(3回出現で最多)
個別の値を指定する場合:
=MODE(5, 3, 7, 3, 9, 3, 5) // 結果:3
複数範囲を指定する場合:
=MODE(A1:A10, C1:C10, E1:E10) // 3つの範囲から最頻値を検索
MODE.SNGLとMODE.MULTの違い
エクセル2010以降では、MODE関数に代わってより機能的な関数が追加されました。
MODE.SNGL関数:MODE関数と同じ動作で、単一の最頻値を返します。
=MODE.SNGL(A1:A10) // MODE関数と同じ結果
MODE.MULT関数:複数の最頻値をすべて返す配列関数です。
=MODE.MULT(A1:A10) // Ctrl+Shift+Enterで配列数式として入力
MODE.MULT関数は、同じ頻度で複数の値が存在する場合に、すべての最頻値を同時に取得できるのが特長です。
MODE関数の利用シーン
アンケート・評価データの分析
顧客満足度調査や従業員評価で、最も多い回答を把握します。
5段階評価の最頻値:
評価データ:5, 4, 3, 4, 5, 4, 3, 4, 5, 4
=MODE(A1:A10) // 結果:4(最も多い評価)
NPS(ネットプロモータースコア)分析:
推奨度(0-10)の最頻値
=MODE(推奨度データ範囲)
=IF(MODE(A:A)>=9, “推奨者が最多”, IF(MODE(A:A)>=7, “中立者が最多”, “批判者が最多”))
売上・取引データの分析
最も頻繁に発生する取引パターンを特定します。
注文金額の最頻値:
=MODE(注文金額データ)
=”最も多い注文金額帯:” & TEXT(MODE(B:B), “#,##0円”)
来店時間帯の分析(時間を数値化):
=MODE(HOUR(来店時刻データ)) // 最も混雑する時間帯
購入個数の最頻値:
=MODE(購入個数データ)
=”最も多い購入パターン:” & MODE(C:C) & “個”
品質管理での活用
製造業で不良品の傾向分析や品質改善に使用します。
不良品コードの最頻値:
=MODE(不良コード番号)
=VLOOKUP(MODE(A:A), 不良コード表, 2, FALSE) // コード名を表示
製品寸法の最頻値:
=MODE(ROUND(測定値データ, 1)) // 小数第1位で丸めてから最頻値
エラー発生時刻の分析:
=MODE(HOUR(エラー発生時刻))
=”最もエラーが発生しやすい時間:” & MODE(D:D) & “時”
在庫管理と需要予測
発注数量や在庫回転の最適化に活用します。
日次出荷数の最頻値:
=MODE(日次出荷数データ)
標準在庫量 = MODE(E:E) * リードタイム日数
発注ロットサイズの決定:
=MODE(過去の発注数量)
=CEILING(MODE(F:F), 10) // 10単位で切り上げ
人事・労務管理
勤怠データや評価データの分析に使用します。
残業時間の最頻値:
=MODE(ROUND(残業時間データ, 0))
=”最も多い残業時間帯:” & MODE(G:G) & “時間”
出社時刻の傾向分析:
=MODE(MINUTE(出社時刻データ)) // 分単位での最頻値
MODE関数の応用・他関数との組み合わせ
COUNTIF関数での頻度確認
最頻値の出現回数を確認します。
最頻値 = MODE(A:A)
出現回数 = COUNTIF(A:A, MODE(A:A))
出現率 = COUNTIF(A:A, MODE(A:A)) / COUNT(A:A)
条件付き最頻値の計算
特定条件下での最頻値を求める配列数式です。
部門別の最頻値:
{=MODE(IF(部門=”営業”, 数値データ))}
期間限定の最頻値:
{=MODE(IF((日付>=開始日)*(日付<=終了日), 数値データ))}
複数の最頻値の処理
MODE.MULT関数を使用した高度な分析です。
上位3つの最頻値を取得:
=INDEX(MODE.MULT(A:A), 1) // 1番目の最頻値
=INDEX(MODE.MULT(A:A), 2) // 2番目の最頻値
=INDEX(MODE.MULT(A:A), 3) // 3番目の最頻値
すべての最頻値を横に展開:
=TRANSPOSE(MODE.MULT(A:A)) // 配列数式として入力
平均値・中央値との比較
データの分布特性を総合的に分析します。
平均値:=AVERAGE(A:A)
中央値:=MEDIAN(A:A)
最頻値:=MODE(A:A)
歪度の簡易判定:
=IF(AVERAGE(A:A)>MODE(A:A), “右に歪んだ分布”,
IF(AVERAGE(A:A)<MODE(A:A), “左に歪んだ分布”, “対称的な分布”))
テキストデータの最頻値(代替手法)
MODE関数は数値のみ対象ですが、テキストの最頻値を求める方法です。
=INDEX(範囲, MODE(MATCH(範囲, 範囲, 0)))
より確実な方法(ヘルパー列使用):
B列:=COUNTIF(A:A, A1) // 各項目の出現回数
C列:=IF(B1=MAX(B:B), A1, “”) // 最大頻度の項目
ヒストグラムとの連携
度数分布表から最頻値を特定します。
階級値の配列:{10, 20, 30, 40, 50}
度数の配列:{5, 12, 18, 15, 8}
最頻階級:=INDEX(階級値, MATCH(MAX(度数), 度数, 0))
動的な最頻値分析
期間や条件を動的に変更できる分析モデルです。
開始日:$D$1
終了日:$D$2
=MODE(IF((日付>=$D$1)*(日付<=$D$2), 数値データ))
MODE関数のよくあるエラーと対策
#N/Aエラーの原因と対処
最も一般的なエラーで、主に以下の原因で発生します。
原因1:数値データが存在しない
=MODE(“A”, “B”, “C”) // エラー:数値がない
対策:
=IF(COUNT(A:A)>0, MODE(A:A), “数値データなし”)
原因2:すべての値が1回ずつしか出現しない
データ:1, 2, 3, 4, 5 // すべて頻度1
=MODE(A1:A5) // エラー
対策:
=IFERROR(MODE(A:A), “最頻値なし(全て同頻度)”)
空白セルとゼロの扱い
MODE関数は空白セルを無視しますが、ゼロは数値として扱います。
ゼロを除外する場合:
{=MODE(IF(A:A<>0, A:A))}
小数データの最頻値
小数点以下の桁数により、同じように見える値が異なる値として扱われることがあります。
対策(丸めてから計算):
=MODE(ROUND(A:A, 2)) // 小数第2位で丸める
大量データでのパフォーマンス
データ量が多い場合、MODE.MULT関数は処理が重くなることがあります。
- 必要な範囲のみを指定
- 揮発性関数との組み合わせを避ける
- 計算結果を値として保存
離散的でないデータ
連続的なデータ(測定値など)では、完全に同じ値が出現しにくいため、最頻値が意味を持たないことがあります。
階級分けしてから分析:
=MODE(ROUNDDOWN(A:A/10, 0)*10) // 10単位で階級化
MODE関数はデータの傾向分析に最適
MODE関数は、データセットの中で最も頻繁に出現する値を求める代表値のひとつを求めるための関数です。アンケート分析、品質管理、売上分析など、実務の様々な場面で活かせます。
MODE.MULT関数を使えば複数の最頻値も取得でき、より詳細な分析が可能です。数値データのみが対象である点に注意し、必要に応じてデータの前処理を行うことが重要です。平均値や中央値と組み合わせることで、データの分布特性を多角的に理解し、意思決定の参考にもなります。
システム乱立を解消するためのステップとは?
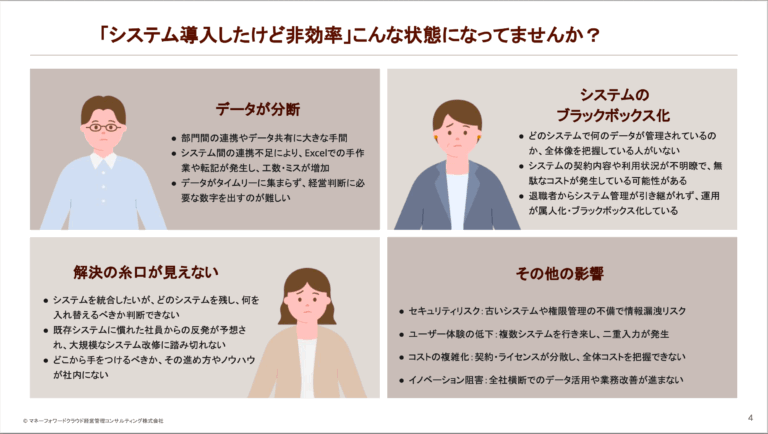
多くの企業がバックオフィス業務効率化のため多様なクラウドシステムを導入するも、「便利なはずが非効率」という現実に直面しています。
その原因は、勤怠や経費など「部分最適」なシステム導入による乱立です。システム同士がつながらず、データの手入力やExcelでの突き合わせ作業が常態化。
これは「見えないコスト」を増やし、業務フローを複雑化させ、現場の負担を増大させます。システム乱立のリスクを整理し、業務アセスメントによる根本解決策をご紹介するホワイトペーパーを用意していますので、ぜひお気軽にご覧ください。
※ 掲載している情報は記事更新時点のものです。
※本サイトは、法律的またはその他のアドバイスの提供を目的としたものではありません。当社は本サイトの記載内容(テンプレートを含む)の正確性、妥当性の確保に努めておりますが、ご利用にあたっては、個別の事情を適宜専門家にご相談いただくなど、ご自身の判断でご利用ください。
Excel 集計・統計関数の関連記事
新着記事
-
# 業務効率化の基本
クラウドのメリット・デメリットは?主要サービスやオンプレミスとの比較表をもとに解説
クラウドのメリット・デメリットは? クラウドは、初期費用を抑えて迅速な導入や拡張ができる点が大きなメリットですが、ネット環境への依存や長期的なコスト増といったデメリットも伴います。…
詳しくみる -
# 業務効率化の基本
社外へのファイル共有を安全に行う方法は?リスクやツール選びのポイントを徹底解説
社外へのファイル共有を安全に行う方法は? 社外へのファイル共有は、機密保持のためクラウドストレージ等の専用ツールを活用し、適切な権限管理と期限設定のもとで行うべき重要な業務プロセス…
詳しくみる -
# 業務効率化の基本
マニュアルの種類は?業務・規範・安全管理など目的別に作成する方法を解説
マニュアルの種類は? マニュアルの種類は、活用目的や対象読者に応じて「業務」「操作」「規範」「教育・訓練」「作業」「製品」「安全・危機管理」の7つに大別されます。 業務・操作: 全…
詳しくみる -
# メモ
Windowsのメモ帳で文字を検索するには?文字列を置換・ファイルを横断検索する方法も解説
Windowsのメモ帳で文字を検索するには? Windowsのメモ帳で文字を検索するには、ショートカットキー「Ctrl + F」を使用するのが効率的です。 検索・置換:Ctrl +…
詳しくみる -
# 業務効率化の基本
ノウハウを蓄積するには?組織の知識を資産に変える方法・仕組みづくり・ツール選びを解説
ノウハウの蓄積方法まとめ ノウハウの蓄積とは、個人の経験や技術(暗黙知)を文書や動画などの形式知へ変換し、組織全体で共有・再利用できる資産に変えるプロセスです。 属人化の解消: 担…
詳しくみる -
# ツール
チャットが苦手だと感じる理由は?原因・特徴・克服するためのコツを徹底解説
チャットが苦手だと感じる理由は? チャットが苦手な主な理由は、即時返信へのプレッシャーや感情が伝わりにくい不安にあり、無理に速度を追わず運用ルールを整えることが克服の鍵です。 脱・…
詳しくみる